Pokemon Fire Red Easy Slot Machine Win
Hands-on Tutorials
How I Beat the Slots in Pokémon Using Reinforcement Learning
Thompson Sampling: It's Super Effective!
Reinforcement learning is providing a huge boost to many applications, in particular in e-commerce for exploring and anticipating customer behaviour, including where I work as a data scientist, Wayfair. One popular way to model problems for RL algorithms is as a "multi-armed bandit", but I have always thought the term was unnecessarily difficult, considering it's supposed to be a helpful metaphor. First of all "one-armed bandit" is 100-year-old slang, and second, the image of a slot machine with multiple arms to pull is a weird one.
Modern slot machines probably do have different buttons to press, that at least pretend to give different odds, but a better metaphor would be multiple machines in a casino, with some being "loose" and some being "tight." When I walked into the Celadon City Game Corner, in the 2004 Gameboy Advance game Pokémon FireRed, and saw rows of slot machines all with different odds, I knew I had found the ideal "real-life" version of this metaphor — and a practical application of reinforcement learning.
(Full code and more detail available in the Jupyter notebook)

And I mean practical! How else am I going to win 4000 coins to buy the Ice Beam or Flame Thrower abilities, which I'll need to fight the Elite Four??
I built a reinforcement learning agent, using Thompson sampling, to tell me which machine to sample next, and, eventually, which one to play the hell out of. I call him MACHAMP: Multi-Armed Coin Holdings Amplifier Made for Pokemon.
How Thompson sampling works
Given a set of possible actions ("arms" of a multi-armed bandit — in this case different machines to try), Thompson sampling optimally trades off exploration vs exploitation to find the best action, by trying the promising actions more often, and so getting a more detailed estimate of their reward probabilities. At the same time, it's still randomly suggesting the others from time to time, in case it turns out one of them is the best after all. At each step, the knowledge of the system, in the form of posterior probability distributions, is updated using Bayesian logic. The simplest version of the one-armed bandit problem involves Bernoulli trials, where there are only two possible outcomes, reward or no reward, and we are trying to determine which action has the highest probability of reward.
As a demonstration of how Thompson sampling works, imagine that we had 4 slot machines, with a 20%, 30%, 50% and 45% chance of payout. Then we can simulate how the solver finds that slot 3 is the best one. Here and in the rest of the notebook, I started from code written by Lilian Weng for her excellent tutorial (everything in the multi_armed_banditmodule is hers).
At the start, we don't know anything about the probabilities of the machines, and assume that all values for their true reward probability are equally possible, from 0% to 100% (depending on the problem, this choice of Bayesian prior might be a poor assumption, as I discuss below).

Estimated probabilities before any pulls:
50.0% 50.0% 50.0% 50.0% One step of the solver involves randomly sampling from the posterior probability distributions of each of the machines, and trying the best one (this is the Thompson sampling algorithm), then updating these distributions based on whether there was a reward.
MACHAMP recommends you try machine 4.
...
Estimated probabilities after 1 pull:
50.0% 50.0% 50.0% 66.7% 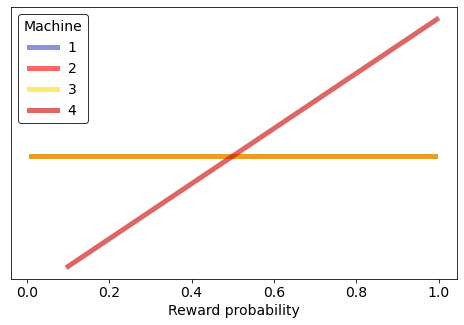
We can see from the graph of the estimated probabilities that one success for machine 4 has made us more optimistic about that machine — we now think that higher guesses for the reward probability are more likely.
After running it for 100 simulated pulls of the four machines, we can see that it's honed in on better estimates of the probabilities.
Estimated probabilities after 100 pulls:
27.3% 35.3% 52.7% 46.2% True probabilities:
20.0% 30.0% 50.0% 45.0%
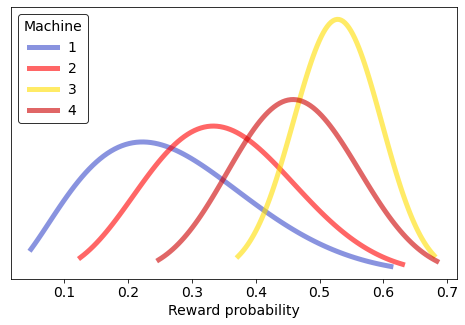
And after 10000 trials we are even more confident that 3 has a high probability of reward, because we sampled 3 much more than the others. We also sampled 4 a lot just to be sure, but 1 and 2 we learned quickly are much worse and so sampled less often — we got less accurate and less confident estimates of their reward probabilities, but we don't care.
Estimated probabilities after 10000 pulls:
14.3% 30.8% 49.4% 45.9% True probabilities:
20.0% 30.0% 50.0% 45.0%
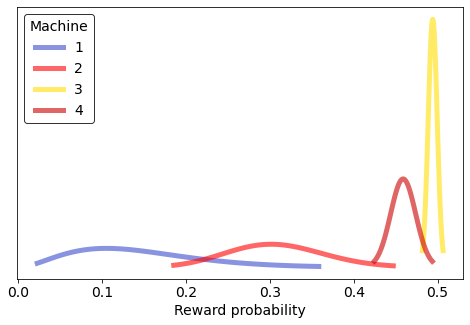
We can use this same exact logic to make the most possible money at the Celadon slots!
Understanding the game and simplifying the problem

There are 19 playable slot machines in the Celadon game corner, which pay off in coins that can be used to buy TMs (Pokémon abilities) and Pokémon that are unavailable anywhere else. Three wheels spin, and you press a button to stop them one at a time, with the goal to line up three of the same picture, or at least a combination that starts with a cherry.
The best jackpot is triple 7s, for 300 coins. How did I know the machines had different odds? Because a game character told me so.
Before going to something as ridiculously complicated as a Thompson sampling MAB solver, I looked online for other advice for beating the casino. Maybe because it's a pretty old game (I get to them when I get to them) the information was sparse and sometimes contradictory:
- The two above the old man are best
- Slot 1 is the best
- The one above the woman on the far left is the best
- You can enter super-lucky mode where you keep winning every 1-2 pulls
- "Play each machine 4 times, and if it hits 2 or more, then stick with that one, because it's probably hot"
Taking these with a grain of salt, I made some simplifying assumptions:
- Each machine has a fixed probability for each outcome
- The probabilities are independent of sequence or time
- The probability of winning anything on a machine correlates to the probability of winning a jackpot (which is my focus)
- Stopping at arbitrary times will sample the space uniformly
Therefore I decided I would play by mashing the "stop" button as fast as possible without paying any attention to the visuals, record only whether it was a win (of any size) or loss, and let Thompson sampling, via MACHAMP, guide my choice of which machine to try next.
Initial systematic exploration
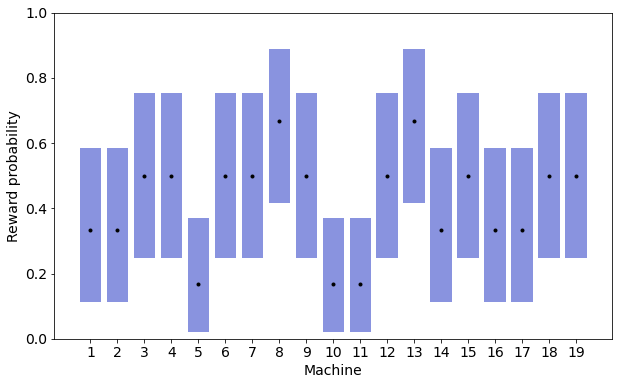
To kickstart the solver, though, I decided to try every machine four times, and use the results to initialize the posterior probabilities. With only four pulls it was hard to draw any conclusions about which were good or bad machines, since the probability distributions overlapped greatly — when they weren't identical.

Since the overlaps made it very hard to read the estimates for individual machines, I instead plotted the credible intervals for each machine: the range of possible values within a certain probability, in this case 80%. It's easy to pick out which machines probably either got 4/4 or 0/4 rewards, and how it is fairly improbable that a 0/4 machine will turn out to be better than a 4/4 machine. Still, a large amount of uncertainty remains, and it's clearly nowhere near enough to pick out the best machine.
Celadon Nights (MACHAMP-guided exploration)
Then I started using the solver to recommend which machine to play next. It was very interesting to intuitively feel the balance of exploration and exploitation as the algorithm sent me from one machine to another, with rewards or no rewards. After each trial I updated MACHAMP with the reward I got (0 or 1), and then asked for a recommendation for which to try next.
Top 5 machines estimated probability:
8: 66.7% (3 out of 4)
13: 66.7% (3 out of 4)
19: 50.0% (2 out of 4)
7: 50.0% (2 out of 4)
3: 50.0% (2 out of 4) MACHAMP recommends you try machine 8. [Tried it, gave a reward, updated MACHAMP] Top 5 machines estimated probability:
8: 71.4% (4 out of 5)
13: 66.7% (3 out of 4)
19: 50.0% (2 out of 4)
7: 50.0% (2 out of 4)
3: 50.0% (2 out of 4)
The trail I made around the casino would have looked pretty wacky, like Billy wandering around the neighbourhood in old Family Circus comics. I was certainly fighting my urges to stick with a seemingly winning machine to the exclusion of all others, and instead randomly leaving the "hot" ones to try seemingly unpromising ones that I hadn't thought about in ages. Humans don't think in Thompson-sampling optimal ways!
Final results
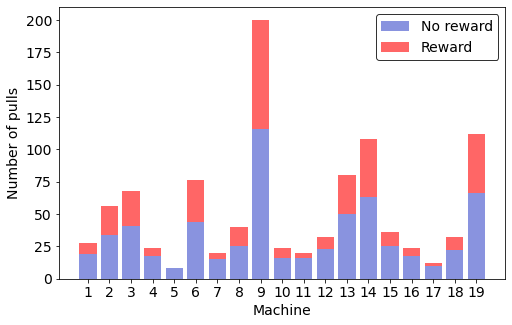
I stopped after 1000 pulls of the slot machine levers, and took a look at what I had learned. First, there was an imbalance in which machines I had sampled, and it was towards the most promising machines based on successes.
The amount of sampling was reflected in the final credible intervals, which were in general wider for the machines that seemed to be worse.
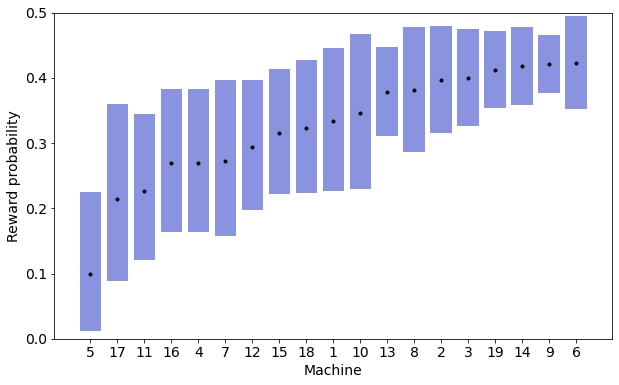
Again these gave a clearer picture than the raw plot of posterior probabilities.

Top 5 machines estimated probability:
6: 42.3% (32 out of 76)
9: 42.1% (84 out of 200)
14: 41.8% (45 out of 108)
19: 41.2% (46 out of 112)
3: 40.0% (27 out of 68) I couldn't be confident which was the very best (like no one ever was), but I could see which were among the best, and how they differed from which were probably the worst, e.g. machine 5, that returned exactly 0 rewards in 8 pulls.
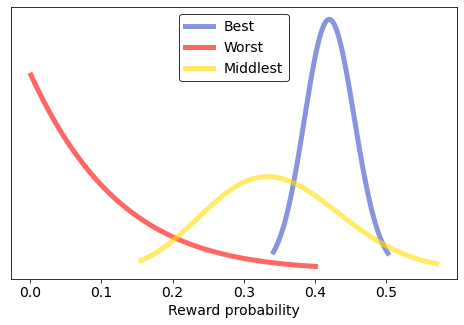
Cashing In
If all I cared about was getting an accurate read on each machine, I could have just spread all 1000 pulls evenly across the 19 machines, 52 pulls each, but this would have led to a lot of lost coins as I kept playing machines that were clearly losers, what is called regret. Although to save time I didn't track my winnings, or even count the jackpots, after 1000 pulls, MACHAMP had amplified my bankroll from 120 to 3977 coins.
Based on these results, I decided to focus on machine 9, which was indeed one of the ones above the old man. It had one of the best estimated reward probabilities (42.1%), but, also important, had a narrow credible interval, thanks to all the times I tried it (119): I could be confident it's definitely among the best.
I did another 1000 pulls just on machine 9, both to test these estimates in practice, and to make that coin. (Also, it was election day, and it was better than hitting reload on the news…) Across all 1119 pulls I won 37.7% of the time, which is noticeably lower than the MACHAMP estimate — though just within the 80% credible interval. I think the algorithm is conservatively biased towards guessing 50%, as a result of the uniform prior (starting with the guess that all values between 0 and 100% being equally likely). Knowing what I know now, that these machines probably don't pay out more than 40%, I could have started with a different prior that would let me get more accurate estimates with the same number of trials.
In any case sticking with this "hot" machine made my bankroll grow!
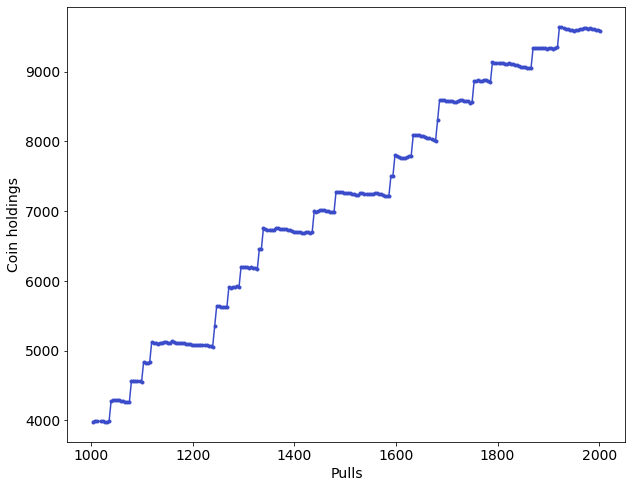
For this period of exploiting machine 9, I started keeping track of my holdings over time, and learned that only jackpots, 300 coins, mattered — the other wins just keep you in the game. I made 5666 coins in 1000 pulls, with 21 jackpots, so machine 9 gave me an expected earning of 5.6 coins per pull. Using the Game Boy Advance emulator at high speed, I could probably do at least 1 pull per second (when I'm not entering results in a spreadsheet, let alone switching machines!) So that's about 336 coins per minute, the equivalent of 1 jackpot. I bet that's actually faster than one method recommended online for making money, of saving the emulator state before each pull (also I arbitrarily decided that feels too much like cheating!)
Conclusion
I walked into the Celadon Game Corner with 120 coins, and walked out with over 10,000. Not only was I able to buy everything I needed to fight the Elite Four, I did it without having to rely on sketchy — and perhaps even superstitious — information from internet forums. MACHAMP gave me a strong read on which were the best machines, in the theoretically most efficient way. A MACHAMP-style solver could be used to play any gambling minigame of this type, which has a collection of choices each with different fixed probabilities of success, starting from zero knowledge. And indeed on any problem that could be modeled that way, such as which of several UI options appeals to users of an app. Just don't think you beat the real slot machines— they're a lot sneakier!
Besides the Shadow Balls, Ice Beams, Flame Throwers, and Porygons I earned, by literally pulling the lever myself each time and seeing how the posterior distributions changed, I got what I was looking for: a gut level understanding of Thompson sampling and Bayesian reinforcement learning. To say it a different way: To catch coins was my real test; to train myself was my cause.
Source: https://towardsdatascience.com/how-i-beat-the-slots-in-pok%C3%A9mon-using-reinforcement-learning-81502e9d6be7
0 Response to "Pokemon Fire Red Easy Slot Machine Win"
Post a Comment